Everything Old is New Again
Apr 15, 2020
This blog was first created in 2003, run off of (as I recall) a PowerMac G4 in
my bedroom. This was before ‘the cloud’, when it wasn’t entirely absurd for
people to run websites off of spare computers in a closet. It was originally
hosted using DynDNS1 at (I think) hamstergeddon.dyndns.org because I had
recently discovered Invader Zim and
I thought the name was funny.2
I chose to run on Movable Type because it was free, customizable, and easy enough for a relative UNIX-neophyte to get running on Mac OS X.
At some point – I think in 2006? I got a real domain name (seankerwin.org)
and moved to a real hosting provider. Time had moved forward quite a bit and
though (to my surprise and delight) Movable Type still existed, it had changed
considerably and my custom page design didn’t translate well. Ever since
‘whenever that was’ the site has been running on a fairly standard MT template
with only minimal modification.
Then the fire nation attacked.
Actually, I quit my job, moved to California, and started working at SpaceX. Which proceeded to eat my free time like some kind of chronovorous monster.
Eventually I – what’s the polite term for ‘burned the frack out’? And I went from delivering stuff to orbit to ‘maybe delivering stuff to Saudi Arabia someday?’ and then to ‘hey buddy wanna rent a scooter’ and dear God when you put it like that it really feels like a slow steady decline, doesn’t it?
Anyway then the scooter thing took a turn for the worse and now suddenly here I am with enough time to work on my blog again, and now we’re all caught up except for the wife3 and the kittens and all the other stuff.
Anyway:
- The iClan page is blank because iClan doesn’t work on modern OS X and somebody else filled the void while I was MIA and I don’t think the world needs iClan anymore.
- The Stylunk page contains the web-based Stylunk that had been
previously labeled ‘beta’ and is now the only version of Stylunk you’ll find
on this site.
- The only thing I touched on web-Stlyunk were the styles – I hit them very hard with a rock to make them fit into the new page layout. There are probably bugs.
- I haven’t updated any of the code since I first posted it 8+ years ago, and in hindsight it’s a horrifying mess. At some point I may rewrite it, because I suspect in TypeScript and React it would be a depressingly short program.
- If there are new clothing colors in Clan Lord since I went AWOL, you are free to submit a Pull Request, because…
- The new site is hosted on GitHub at
https://github.com/skirwan/skirwan.github.io
- It’s built on Jekyll and hosted through GitHub Pages.
I have like three different folders full of ‘blog post ideas’ that I’ve been saving for the past eight years; hopefully I’ll get some of them published before I end up employed again4.
-
Circle of life, right? You’re good, you’re popular, you’re bought by Oracle, time passes… I’m surprised you still exist and how expensive you are. ↩
-
That this statement is in the past tense should not be interpreted to imply that I do not presently find the name ‘Hamstergeddon’ hilarious. ↩
-
My two favorite things are ‘putting serious and important things in a place where the reader has been led to expect unimportant information’ and ‘my lovely wife’, and I’m sure she won’t mind that I’ve done a little crossover episode here, right? ↩
-
This statement is made in jest, but I am well aware that I’m very privileged to be able to say this jokingly. ↩
The Knight and the Will
Oct 4, 2017
Once upon a time there was a knight in the service of a great lord.
One morning, as he was standing guard at the drawbridge to his lord’s castle, a brigand came down the road and attempted to pass by him. As was his knightly duty, he silently drew his sword and blocked the brigand’s path. His lord was quite wealthy and the castle was elsewise undefended, and brigands frequently made halfhearted attacks at fighting their way past him into the castle. But he was a formidable knight, and none could best him in battle.
“Hello!” exclaimed the brigand, nodding vigorously. “I appreciate your diligence! Marvelous security!”.
The knight cocked his head and let out a perplexed grunt despite himself. This was not, in his experience, typical brigand behavior.
The brigand, meanwhile, was nearly vibrating with excitement: “Yes, I appreciate it a great deal! The safety of my castle is paramount, and I’m quite glad to see you doing your duty.”
The knight was so surprised he dropped his fierce mien and let slip the first word that came to mind: “What?!”
“Oh yes, I do appreciate a go-getter. We’ll get on well!”
“I’m afraid you must be under some form of misapprehension, sir. This is in fact the castle of my great lord, and I am his defender. Now be on your way!”
“Marvelous, marvelous!” exclaimed the not-at-all-ordinary brigand. “Well said, well said. Except: I’ve here a document, saying that this castle is in fact not the property of your lord, but rather my property.”
A moment passed.
“Pardon?” asked the knight.
This was news to him, and he was by now so wrong-footed he had quite forgotten to be fierce.
“Yes, it’s all in here I’m afraid,” replied the brigand, waving a large leather-bound tome around somewhat negligently. “You see, the last will and testament of your lord’s great-great grandfather contained a clause stipulating some rather complex rules for succession.” The brigand’s voice dropped as he added in a proud, conspiratorial whisper: “It’s taken quite some time to un-puzzle it in fact.”
The brigand went on to explain that the heavy, bound document was in fact the will in question, and that it contained a lengthy series of complex puzzles, clues, quizzes, and codes that specified how the great-great-grand-lord’s property was to be disbursed. He shared with the knight the bundled papers on which he had sought to solve the mystery, and helped walk him through the complex reasoning that led the man to his claim of ownership. The two sat together for hours, poring over the complex question and seeking the truth of the puzzle.
The sun was slipping lower in the sky when finally the knight arose in triumph and let out a cry of excitement.
“Aha! I see it!” he exclaimed. “You’ve absolutely right in your solution to the puzzle on page seven… but your erred slightly in the acrostic on page nineteen, which means your inferred clues to the quiz on page eighty-one led to an incorrect code for deciphering page one-hundred-eleven! The castle is still the property of my lord!”
The brigand’s face fell as he frantically flipped through pages and verified the knight’s objection.
“You’re absolutely right,” he finally admitted. “I guess I’d best go. Thank you for your patience!”
“Not at all,” replied the knight, genuinely pleased to have resolved the sticky issue and already looking forward to the praise his lord would doubtless heap upon him for his diligence. “Not at all!”
The brigand turned and began walking away.
The knight stood, raised his arms over his head and stretched the mighty stretch of an active man who’d spent the day doing puzzles cross-legged on the ground. He leaned left and right, pulled his arms in front of his torso and behind, stood tip-toed on each leg in turn, and only then, fully limber, did he chance to turn around and see, for the first time in hours, his lord’s castle.
And the hastily-assembled log bridge that the brigand’s compatriots had levered across the moat while he was distracted.
And the ladder they had climbed over the castle wall.
And his lord’s corpse, hanging out the tower window, dripping blood on the parapet below.
Once upon a time there was a knight.
He was of no service.
He had had no lord.
But he had learned a very important lesson: Never let your opponent dictate the arena of the conflict.
Lazy-R-Us
Dec 3, 2016
Is this thing on?
Scenes From an Interview
May 17, 2013
“Obviously the job requires some pretty serious math skills. As the first-line screener, my job is basically to do a sanity check and make sure that you meet the baseline we’re looking for, so that we don’t waste our time and your time with further interviews that aren’t going anywhere. I see you’ve got an impressive resume and a lengthy career, so please don’t be offended if my questions seem simple; it’s not ajudgementon you, but a reflection of the goal here. Any questions? No? Good.”
“So here’s my first questions: What’s one plus one?”
Loser answer number 1:
“Geez… I don’t think anybody’s asked me to add one and one since elementary school. Is that really something you do? I’ve been working in this field for twenty years now, and I don’t think I’ve had to know one plus one even once… any competent professional has Excel, or a calculator, or _something_that will take care of details like that for them. I’d go so far as to say that anybody who’s manually adding single digit integers like that probably should be fired.”
Loser answer number 2:
“Oh, I remember this one! I haven’t actually done one plus one since kindergarten, but I studied up on the basics before this interview, and I remember that the answer is two. Here, let me write a two for you… It’s kind of curvy around the top, I think, like this… no, more like… here we are, that’s a two.”
Loser answer number 3:
“Eleven. Yes, I’m sure. No, there are no problems with my answer. You put the two ones next to each other, and it’s eleven. What the hell is wrong with you?”
The humor here’s pretty obvious, right? No reasonable person misses the fundamental problem with these answers, I hope. Any yet if you shift the field to computer science, suddenly people think these sorts of shenanigans are reasonable.
Of course nobody would implement ELEMENTARY_DATA_STRUCTURE_1 by hand in this day and age; it’s in the standard library on any platform worth dealing with (well… maybe not Cocoa…) and the folks writing the library probably spent a lot more time debugging and optimizing than you’ll ever be able to devote. You don’t get asked to implement these things because the interviewer’s going to steal your code and check it in to source control.
And you also don’t get asked because, gosh darn it, we totally need an idiot with an eidetic memory who can vomit code snippets he doesn’t understand. We have Google for that! We’re not testing your memory, but your ability to understand basic computer science principles and - gasp - write code! If you don’t have the code paged into memory right now, from our perspective that’s a HUGE WIN. We want to watch you re-derive things from fundamentals, not regurgitate all over Collabedit.
Dispatches from a Displaced Floridian: Part 1
Jul 15, 2012
I hate seeing both sides of a thing.
Air conditioning feels to me like more than a modern convenience. It’s the sort of thing that I expect every freestanding structure to have, and the lack of AC is to me as disconcerting as the lack of electricity must have seemed in the near-recent past, when ‘everyone’ had it but literally everyone didn’t yet have it.
AC is about more than cooling; it’s about your air being cleaned and circulated. Your air is, for lack of a better word, conditioned. It gives me a feeling of protection to know that a building is relatively air-tight and that the oxygen supply is being regulated. There’s a wild, untamed outside, where the insects and arthropods and germs and smoke and pollution and other anarchist elements can have their day, and there’s the nice, soothing, controlled inside where I can have my books and WiFi and TiVo and peace and quiet. It’s a wall.
A largely illusory and highly ineffective wall, to be sure. But it’s making a stand; drawing a line. Out there: chaos; in here: the homey disordered order that defines my comfort zone.
And of course in asserting all this, I know full well that I’m being silly. I sound like a science fiction cliché — one of Asimov’s bubble-dwellers who refuse to believe the world outside is even habitable, of perhaps someone out of Brave New World. And while I can recognize intellectually that I am — on this point at least, and possibly on many others — stark raving mad, that doesn’t in any way negate the underlying impulse. Knowing I’m crazy doesn’t make me sane, it just makes me annoyed at the insufferably buggy firmware with which God or evolution or the Engineers has saddled me.
Web Stylunk: Palette-Recoloring Sprites with HTML5
Dec 21, 2011
Quick background info, or ‘what the hell is a Stylunk?’
I play Clan Lord, a multiplayer online RPG. Clan Lord provides a lot of ways for players to customize their characters’ appearance, including a system for changing shirt and pants colors with an algorithmic dye and bleach system. Experimenting with dyes and bleaches in-game can be prohibitive — each application consumes in-game currency and (often rare) materials. As a result, there’s a long tradition of external dye-simulation tools; the earliest was Stylus (named in the ‘function-us’ pattern of many Clan Lord NPCs), followed by Stylos, the OS X re-imagining of Stylus. Stylos didn’t work well on Mac OS X 10.4 Tiger, so in 2005 I built the first version of Stylunk as a replacement.
Since then the number one Stylunk-related request has been for a Windows version, and the number two request is ‘hey, add this new shirt color!’. Both of which were difficult enough to fill that they happened never (Windows version) and only intermittently. So I’ve decided to simplify cross-platform concerns and centralize updating by turning Stylunk into a web app. The beta is right here.
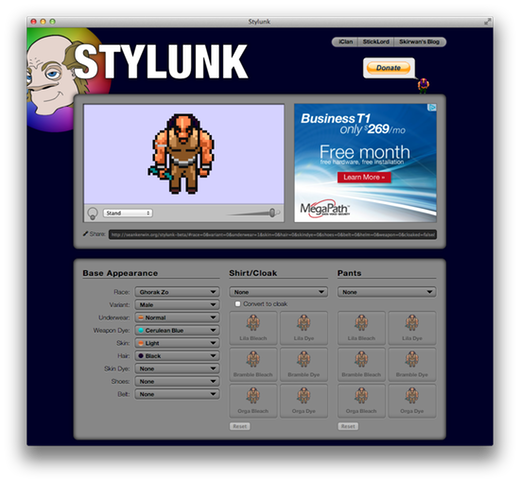
Palettized recoloring in JavaScript or ‘the actual non-background stuff about which I plan to write’
I started playing Clan Lord in 1998 and it had already been in development for a while at that point, so it shouldn’t be a surprise that the tech isn’t exactly modern. Images in Clan Lord are an run-length-encoded list of indices into a per-image color map, which itself contains indices into the ‘Mac standard’ 256 color map. That’s all pretty integral to Clan Lord, because character customization is implemented as a set of 20 color overrides for the per-image colormap: indices zero and one contain the highlight and shadow colors for the character’s hair, for instance.
Images for a particular icon are arranged into a single 16x3 sprite sheet, comprising the 32 standing/walking/running sprites in eight cardinal directions as well as a ‘dead’ sprite and fifteen ‘poses’ that players can activate to emote. Here’s what the ‘Ghorak Zo’ sprite sheet looks like:
![]()
My first stab at implementing web Stylunk was about what you’d expect: I converted each of the sprite sheets into PNG files and wrote code that draws the selected sprite into a canvas, iterates across the pixels, and replaces the ‘default’ colors with the mapped values calculated from the current UI selection. Then I created a smaller canvas, copied the frame I needed from the large canvas to the small canvas, and used toDataURL() to extract something that I could stick into the background-image of my buttons.
It all worked fairly well, at least at first. On my main machine (a Core i7 Mac Mini) everything was peachy. On my MacBook Air, it was sluggish. On my iPad… well, the less said the better.
My immediate response was to try some very aggressive caching, leading to the creation of a reusable JavaScript least-recently-used cache. That helped, but not as much as I’d hoped.
My next thought was: I’m doing more work than I need to: there’s no point colorizing the entire sprite sheet and then only displaying a single frame of it. So I swapped things around; first extract a small canvas from the larger, then recolor only the smaller canvas. That helped too, but it was still pretty logey on the iPad.
Unfortunately there’s no way to profile JavaScript in MobileSafari. But desktop Safari does have a profiler, and it showed something interesting: the slowest part of the process was reading the pixels out of the initial canvas. So I took a cue from Clan Lord and took a step back in time: instead of storing the images as PNG sprite sheets, I wrote a tool that converts each frame of the sheet into a JavaScript data structure containing a run-length encoded bunch of pixel indices. That way I can skip the ‘reading from canvas’ step, and jump straight to writing them. I also took the step of storing each frame as a separate JavaScript file which the main app loads on-demand via XMLHttpRequest, which simplifies the caching a lot by letting the browser do the work.
If you’re curious, you can take a look at the code for a sprite here. That’s my JS-encoded version of the male Ghorak Zo facing east — the top-left sprite in the image above. Yup! — despite being larger than a PNG representation or the same image, and despite needing to be parsed by the JavaScript engine, it still ends up being faster than reading data back from a canvas.
The end result is that Stylunk runs at a usable speed on my iPad (first-gen) and on my iPhone 4, which is good enough for me. There are still some minor inefficiencies as a result of the tortured path to the current architecture — if I were doing this from scratch there would also be JavaScript representations of the character color maps, which would simplify the color mapping process and also allow me to easily draw characters using the color map data from the XML data feed powering the Clan Lord Informer and iClan.
I’m actually half-tempted to do that, because it would provide a starting point for building a Socket.IO- and Node.js-powered HTML5 Clan Lord client. But that’s a headache for another day.
A Simple JavaScript Least-Recently-Used Cache
Dec 21, 2011
In the course of a recent quick JavaScript side-project — post forthcoming — I needed a simple cache. Then I needed another cache within the cached objects. Then I needed another cache. It was at that point that I realized I should probably factor things out into a reusable component, and built JSLRU.
Of course then I refactored things dramatically and it’s barely used at all. But if you need a JavaScript least-recently-used cache, check it out.
Generic Accumulators in C#, Redux
Dec 21, 2011
It turns out one of the most-trafficked pages on this site is my discussion of generic accumulators in C#. It occurs to me that it could use a bit of an update, as some newer features like lambdas and the predefined Func<> family simplifies things quite a bit:
class Program
{
public static Func<T, T> MakeAccumulator<T>(T start, Func<T, T, T> addFunction)
{
return inc => start = addFunction(start, inc);
}
static void Main(string[] args)
{
var intAccumulator = MakeAccumulator(0, (i, j) => i + j);
Debug.Assert(0 == intAccumulator(0));
Debug.Assert(1 == intAccumulator(1));
Debug.Assert(11 == intAccumulator(10));
Debug.Assert(55 == intAccumulator(44));
var floatAccumulator = MakeAccumulator(0.0, (i, j) => i + j);
Debug.Assert(0 == floatAccumulator(0.0));
Debug.Assert(0.1 == floatAccumulator(0.1));
Debug.Assert(1.1 == floatAccumulator(1.0));
Debug.Assert(5.5 == floatAccumulator(4.4));
var stringAccumulator = MakeAccumulator("", (i, j) => i + j);
Debug.Assert("" == stringAccumulator(""));
Debug.Assert("ZYZ" == stringAccumulator("ZYZ"));
Debug.Assert("ZYZZY" == stringAccumulator("ZY"));
Debug.Assert("ZYZZYVA" == stringAccumulator("VA"));
Console.WriteLine("Success!");
Console.ReadLine();
}
}
So there’s that. Still not terribly useful, but I do like shortening code.
What Do You Call One Dead Terrorist?
May 2, 2011
“A good start.”
Bad, old jokes aside:
I’ve said it before, and I’ll say it again: the Bush War on Terror was never about hunting down bin Laden. To view it in that light is to characterize it as a campaign of retribution rather than one of pre-emptive self defense. It is a simplistic and reductionist misrepresentation favored primarily by those who opposed Bush in every fashion, and it’s a straw man that we would all do well to stop stuffing.
Some people make the world better through their existence, some make it worse, and the vast majority of us largely break even. Osama bin Laden was clearly in the ‘worse’ column, and in that sense the world is a better place with him a corpse. But to claim that his death in any measurable way makes us safer or surer or more just is folly.
Should’ve Bought an Xbox
Apr 26, 2011
I bought a Playstation 3 a few years back (when I got my HDTV, as I recall) primarily to use as a blu-ray player (at the time it was actually cheaper than a standalone player). As Sony doubtless expected, it entered my home as a shiny black Trojan horse, and I’ve bought a handful of games since then.
Including, fatefully one from the Playstation Network (link goes to a Flash-only site, because Sony’s just in full-on pissing-me-off mode at the moment).
If you’re reading this there’s roughly a 99% probability that you already know that the PSN has been ‘out’ for nearly a week, and the latest news from Sony is that it ain’t comin’ back anytime soon, and oh, by the way, some hackers probably have your credit card numbers.
I know this the same way you do, through the magical collaborative power of the Internet. Not, say, from an email sent to me by Sony warning me that my credit card number had been stolen. Strike one, Sony. You assholes.
But as annoying — and probably actionable — as their failure to proactively warn their customers may be, that’s not what really pisses me off.
No, what’s really bugging me is that I can’t use Netflix on my PS3.
Why? Because Netflix on the PS3 — despite being tied to my totally independent non-Sony Netflix account — requires a PSN login to function. For no reason at all except that Sony are a bunch of goddamned morons.
Thank God for the Apple TV.